Our project provides a new novel method that combines the Hierarchical Actor-Critic (HAC), which requires designing the sub-goal spaces with prior knowledge and the regularization of the sub-goal representation learning that does not require prior knowledge due to the
stable learning of the sub-goals. The proposed method, in some configurations, does slightly improve the performance. HAC performs well in uncomplicated environments but poorly in challenging ones. With more extensive experimentation, our method would help solve complex tasks without any need to update subgoals for each new task.
Reinforcement Learning (RL) has proven its success in many simulated and real-world problems. Nevertheless, many algorithms of RL are still slow, especially if the rewards given to the agent are sparse (Levy, Platt, & Saenko, 2017). Hierarchical Reinforcement Learning (HRL) is a computational approach in which the problem is divided into sub-problems, which helps considerably with problems with large action and/or state space (the Curse of Dimensionality problem; Levy, Platt, & Saenko, 2017). For instance, to make a cappuccino, we need to perform many sub-tasks that seem trivial to humans, such as walking toward the place where the cup is. This sub-task includes other sub-tasks, such as activating the muscles in the legs to bend the knee, lift the foot, etc. This is a long sequence of actions to achieve the end goal – having a cup of cappuccino. And in each step, there is an enormous amount of alternatives one could do.
Policies for such problems involving long sequences of actions with few rewards are challenging to learn (Levy, Platt, & Saenko, 2017). In these cases, a higher level of temporal abstraction is required, i.e., dividing the problem into sub-problems (Levy, Platt, & Saenko, 2017). In the previous example, moving toward the coffee jar is considered a sub-problem or a temporally extended action because it may take numerous steps or sub-actions (Flet-Berliac, 2019). HRL also allows for transfer learning (Flet-Berliac, 2019), meaning sub-tasks can be reused for a different task in the same domain. For instance, learning how to make a latte shares many sub-tasks with the previous example; thus, the agent does not need to learn all the sub-tasks, but only the sub-tasks that are different. Additionally, HRL provides a structured exploration: the agent explores using the sub-goals rather than the primitive actions, which leads to faster learning of the final policy (Flet-Berliac, 2019; Levy, Platt, & Saenko, 2017).
Our goal in this project is to combine two improvements (Section 3) to the Hierarchical Actor-Critic (HAC) approach (Section 4). Based on this combination, we perform experiments within four different environments (Section 5) and analyze the results (Section 6).
2 Related Work
Our work builds upon two papers, Röder et al., 2020 and Li et al., 2022, which are explained in more detail in Section 4.
HRL, being one of the many RL approaches, tackles big action spaces and sparse reward problems (Levy, Platt, & Saenko, 2017). However, even within HRL, there are many different sub-approaches and frameworks aside from the here-used Hierarchical Actor-Critic approach (Levy, Platt, & Saenko, 2017). One of those is the Option-Critic Framework (Bacon et al., 2017), an alternative architecture that learns both the internal policies and the termination functions without specifying option sub-goals or sub-rewards (Taschin, 2016). This approach, however, showed poor generalization capabilities and, therefore, is not re-applicable to tasks with other configurations. Another approach is Feudal Hierarchical Learning (Dayan & Hinton, 1992). Originally applied to a maze task, it uses managers to set goals for sub-managers who, in turn, have their own sub-managers and so on, all of which try to follow solely their manager's instructions and do not know the overarching goal. As with many HRL approaches, it suffers from several problems. Most notably, the hierarchy levels are only learned one by one, which is very inefficient (Levy, Konidaris, et al., 2017). Hierarchical Actor-Critic solves this and other problems, as explained in Section 4.
While HRL has been an existing and established approach for more than two decades (Kaelbling et al., 1996), HAC was only introduced in 2017 (Levy, Konidaris, et al., 2017), though there are already several extensions and applications built upon it, including not only those combined in this work but also others, such as the Twin Delayed HAC (Anca & Studley, 2021). The former adds several techniques to make HAC work in pick-and-place environments while the latter applies HAC to mobile robots.
For both curiosity and regularization, there exists a large amount of work in non-hierarchical RL contexts.
3 Proposed Method
We focus on the relatively new approach of HAC and combine two promising improvements of HAC, namely curious HAC (Röder et al. 2020) and the regularization of the sub-goal representation learning in the active hierarchical exploration (Li et al., 2022). Both approaches improve the performance of HAC in certain environments. However, the method proposed by Röder et al., 2020 requires designing the sub-goal spaces with prior knowledge (Li et al., 2022). The method by Li et al., 2022 does not require prior knowledge due to the stable learning of the sub-goals. The motivation of this project is to find out if the combination of both approaches leads to further improvement, if it is redundant, or if it is better to keep these approaches separate. To this end, we perform experiments and ablation studies.
The first improvement is the curious hierarchical actor-critic (CHAC). This approach was chosen due to its better performance over the vanilla HAC architecture in most tested environments and being a generally well-performing approach in non-hierarchical RL (Röder et al. 2020). To mitigate the sparse reward problem, it combines the Hindsight Experience Replay (HER) method and a curiosity-driven exploration. The latter method provides rewards when the agent is surprised, and the agent is surprised when its internal prediction differs from the actual environment dynamics. In addition, the authors made their code publicly available 1 and provided suitable and challenging environments for HRL algorithms. This enabled us to build upon their implementation of HAC and Curious HAC.
The second improvement is goal-conditioned hierarchical reinforcement learning (GCHRL), which is a promising approach when solving temporally extended tasks. In GCHRL, a high-level policy assigns sub-goals to a low-level policy. The low-level policy receives an intrinsic reward every time it reaches the sub-goal. Generally, in HRL, task decomposition results in a good performance. However, GCHRL methods still struggle with long-horizon tasks due to the sparse reward problem, i.e., gaining external rewards and exploring at a high level is still a hard task. Furthermore, the online-learned sub-goal space has proven to be unstable and challenging for exploration (Li et al., 2022). To solve these issues, an active Hierarchical Exploration approach with Stable Sub-goal representation learning (HESS) was proposed. We chose HESS as our second improvement to the HAC architecture.
4 Theoretical Background
In this section, we first introduce the vanilla HAC architecture and its main components. Then we revise concepts presented in the following frameworks: Curious HAC and regularization of the sub-goal representation.
4.1 Hierarchical Actor-Critic
The HAC algorithm helps the agent to solve long-horizon problems, i.e., problems that require a large number of time steps until a terminal state is reached (Russell & Norvig, 2020), which is a difficult for many non-hierarchical and hierarchical approaches (Pateria et al., 2021).
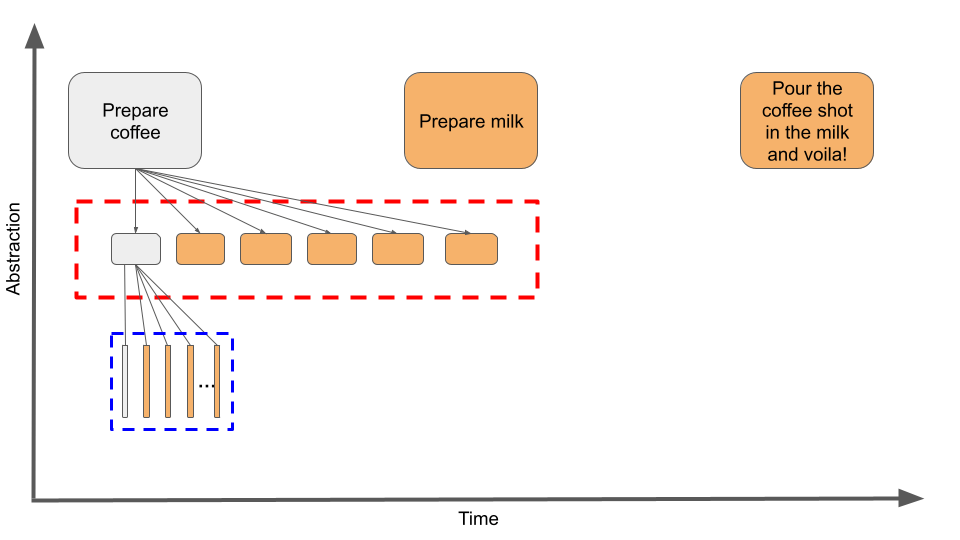
Figure 1: Example of HAC hierarchy. An agent divides the problem into sub-problems of different temporal resolutions using three policies.
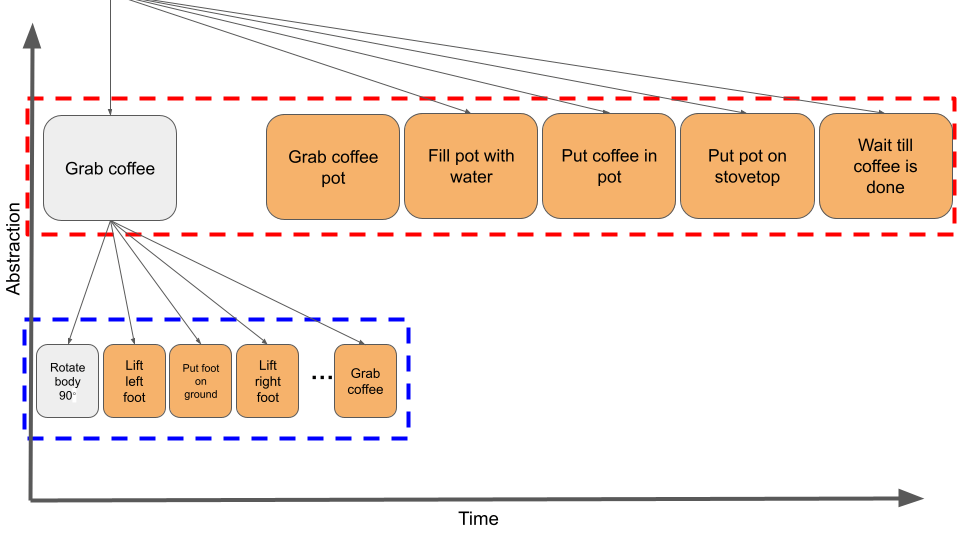
Figure 2: Example HAC Hierarchy. The third policy divides the sub-goals, that are given by the second policy, into sub-goals of finer time resolution.
HAC is an approach to HRL which enables the agent to divide a problem with continuous state and action spaces into simpler sub-problems of different time scales (Levy, Platt, & Saenko, 2017). In Figure 1, we see the example of preparing a cappuccino solved hierarchically where the agent reaches the end goal, namely having a well-prepared cappuccino, using three policies. Each policy outputs less-abstracted sub-goals. For instance, to prepare coffee, the agent needs to take the coffee, bring the pot, fill the pot with water, put some coffee inside the pot, place the pot on the stovetop, and finally wait until the coffee is done (Figure 2). The mid-level policy divides each sub-goal given by the high-level policy into sub-goals belonging to less-level of abstraction. While the low-level policy decomposes the sub-goals of the higher-level policy into actual agent actions, the actions represent the smallest time resolution (Levy, Platt, & Saenko, 2017). The reason for decomposing a long policy into shorter sub-policies is because short policies learn faster than long ones, and the agent learns multiple policies in parallel (Levy, Platt, & Saenko, 2017).
4.2 Universal Value Function Approximators
HAC solves the problem of sparse rewards using a technique from the RL literature called the Universal Value Function Approximators (UVFA) (Schaul et al., 2015), where it adds to the action-value function an additional term to represent goals:
This function stands now for the expected rewards when performing \( a_{t} \) in \( s_{t} \) to achieve \( g_{t} \). UVFA incorporates the goals, where each goal has its own reward function \( r_{g}(s_{t}, a_{t}, s_{t+1}) \) and discount function \( \gamma_{g}(s) \). When reaching a state \( s \) that achieves the goal <\( g \), \( s \) can be considered as the terminal state \( \gamma_{g}(s) = 0 \). Incorporating the goals is implemented by extending the Markov Decision Problem (MDP), which is defined as a tuple \( (S, A, R, T, \gamma) \), where \( S \) is a set of states, \( A \) is a set of actions, \( R : S \times A \) is a reward function, \( T: S \times A \rightarrow \text{Pr}(S) = p(s_{t+1}|s_{t}, a_{t}) \) is a transition probability function for reaching \( s_{t+1} \) from \( s_{t} \) when performing \( a_{t} \). Therefore, Universal Markov Decision Problem (UMDP) is similar to MDP but with goals added to the tuple, \( (S, G, A, R, T, \gamma) \).
4.3 Hindsight Experience Replay
In a scenario where an agent has to observe an environment with a sparse reward setting, it must uncover a long sequence of random actions before it can learn the optimal policy. Another way to solve this problem is to apply a Hindsight Experience Replay (HER) technique. Combined with an off-policy algorithm (e.g., DDPG), it can learn from sparse and binary rewards (Ciaburro, 2018).
Let's go back to our cappuccino example. If, for instance, our agent aimed to add some milk to the coffee cup but instead poured it slightly to the left of the cup's border, the standard reinforcement learning algorithm would see the whole sequence of the agent's actions as unsuccessful. However, had we placed that cup of coffee a little bit to the left, the same line of actions would have been considered successful. This scenario requires an algorithm that doesn't learn from reward shaping, but from binary rewards (e.g. successes or failures). Learning from failing to achieve the goal state can be as telling as achieving one, i.e., the action trajectory simply needs to be adjusted. To implement this logic, the HER technique is used. HER can be used for multiple goals. It improves the sample efficiency, learns from sparse and binary rewards, and is based on training universal policies (i.e. taking both the current state and goal state as an input) (Andrychowicz, 2017).
Implementing HER in a hierarchical manner requires the following three kinds of state transitions (Röder et al., 2020):
Hindsight goal transitions: As we mentioned before, pretending in hindsight that the actual achieved state is the goal state helps the critic to encounter at least one reward after a sequence of actions.
Hindsight action transitions: The previous transitions are generated by pretending in hindsight that the performed action, which is the sub-goal of the low-level layer, has been reached. Thus, it enables HAC to learn multiple levels of policies in parallel without waiting for the low-level policies to complete their training. In addition, it solves a drawback of classical HRL, namely slow learning due to the sparsity of achieving the actual sub-goals provided by the higher-level policies.
Sub-goal testing transitions: They are used to test if the sub-goals given to the lower-level policy are achievable by penalizing a sub-goal that cannot be achieved. Thus, all difficult sub-goals are penalized at the start of the training. Fewer sub-goals are penalized as the agent's performance has improved.
Combining all three components creates the HAC formal framework (Röder et al., 2020): Define a hierarchy of \( k \) layers, where each layer has an actor model and a critic model together with a replay buffer to save the gathered experiences. To extend RL in a hierarchical setting, we need to represent each layer as a UMDP, \( U_{i} = (S_{i}, G_{i}, A_{i}, R_{i}, T_{i}, \gamma_{i}) \)(Levy, Platt, & Saenko, 2017). The state space of all layers is identical to the original \( U_{\text{original}} \). \( A_{t0} = A \) because only in the lowest layer does the agent perform primitive actions within the environment (Levy, Konidaris, et al., 2017). The action space in the other layers is equal to the goal space of the next lower layer. The goals in all levels, except the top level, will be dictated by UMDP of the higher levels. Given that every state is a potential goal, these goals are defined as \( G_{i} = S \). The top level's goal set is provided by the task \( G_{k-1} = G \)(Levy, Konidaris, et al., 2017). The reward function at level 0 can be any value, but Levy, Konidaris, et al., 2017 used a reward of 0 if the next state maps to the goal and a penalty of -1 otherwise.
4.4 Deep Deterministic Policy Gradient
One of the most challenging tasks in reinforcement learning is to solve complex real-life tasks coming from unprocessed, high-dimensional input. For instance, solving physical control tasks requires real-valued, continuous, and high-dimensional action spaces (Lilicrap, 2015). To tackle this type of task, the Deep Deterministic Policy Gradient (DDPG) algorithm was introduced. It is a model-free reinforcement learning algorithm for continuous spaces, which consists of two networks: actor and critic. It learns both the Q-function from off-policy data and the Bellman equation, as well as a policy from the Q-function. In DDPG, the function \( Q^{*}(s,a) \) is differentiable with respect to an action \( a \). Thus, we can make use of the gradient-based learning rule for a policy \( \mu(s) \) and approximate \( \max_{a}Q(s,a) \approx Q(s,\mu(s)) \)(OpenAI, 2018).
In this section, we will have a closer look into the math behind DDPG from two perspectives: learning a Q-function and learning a policy. The Bellman equation can approximate the \( Q^{*}(s,a) \):
\[
Q^{*}(s, a) = \mathbb{E}_{s' \sim P} \left[ r(s, a) + \gamma \max\ _{a} Q^{*}(s', a') \right]
\]
Denote \( Q_{\phi}(s,a) \) with parameters \( \phi \) as the neural network approximator and \( (s,a,r,s',d) \) as a set of transitions \( D \). Therefore, the mean-squared Bellman error (MSBE) function shows us how closely \( Q_{\phi} \) satisfies the Bellman equation:
\[
L(\phi, D) = \mathbb{E}_{s, a, r, s', d} \left[ \left( Q_{\phi}(s, a) - \left( r + \gamma (1 - d) \max'\ _{a} Q_{\phi}(s', a') \right) \right)^2 \right]
\]
We can see that the Q-learning algorithm, such as DDPG, aims to minimize the MSBE loss function (OpenAI, 2018). To do that, DDPG employs certain techniques:
Experience Replay Buffer: To approximate \( Q^{*}(s,a) \), DDPG makes use of a fixed-sized experience replay buffer that contains past transitions collected by the policy. It improves the sample efficiency by reusing the data many times during the training and contributes to the stability of the network (Fedus et al., 2020).
Target Networks: When the MSBE loss is minimized, the \( Q \)-function becomes closer to the target value. The target is dependent on the training parameters, which makes the MSBE minimization unstable. The solution is to use parameters close to \( \phi \) and create a second network with a time delay that falls behind the first one. However, in continuous action space, maximizing \( Q_{\phi_{\text{targ}}} \) is challenging. Thus, Polyak averaging is applied (OpenAI, 2018).
From the policy learning side of DDPG, a deterministic policy \( \mu_{\theta}(s) \) that provides the action to maximize \( Q_{\phi}(s,a) \) needs to be learned. As mentioned earlier, in continuous action space, the Q-function is assumed to be differentiable—thus, we can apply gradient ascent to solve:
In reinforcement learning, the sparse reward problem occurs when the agent does not observe a sufficient amount of reward in the environment and, therefore, cannot learn from its actions. To solve this problem, inspiration was taken from human behavior by observing that humans not only maximize their rewards externally, for instance, by getting food from their environment but also by being intrinsically curious and motivated to explore solely to understand the nature of things. Curiosity may be seen as an intention to reduce the uncertainty in the environment (Zai & Brown, 2020) or, equally, an agent's motivation for exploring novel states (Pathak et al., 2017). In this section, we will look more closely into a combination of hierarchical abstraction and curiosity-driven exploration. The two approaches are yet rarely combined; however, both are aimed at solving the sparse reward problem Röder et al. (2020).
The HAC architecture combined with the curiosity rewards contains a multi-layered perceptron that learns the next state \( \hat{s}_{t+1} \) given the current step \( s_{t} \) and action \( a_{t} \) at a time step \( t \), where \( \theta \) represents the model parameters (Röder et al., 2020).
:
One forward model \( f_{\text{fw}}^{i}(s_{t},a_{t}^{i};\theta^{i}) \) is implemented per layer. Here, the subgoal for the subsequent layer is defined by an action \( a_{t}^{i} \) produced by a policy \( \pi_{i} \) from the layer \( i \) at a time step \( t \), as shown in Figure (Figure 3). The training goal is to minimize the prediction loss:
:
This prediction error of the layer \( i \) is used to calculate the curiosity reward \( r_{c,t}^{i} \). The mean-squared-error is calculated as follows (Pathak et al., 2017):
The extrinsic rewards received from the environment are set within a \([-1,0]\) range. It means we would need to normalize the curiosity rewards we get from the equation above. To perform the normalization step, we consider the buffer-stored values corresponding to the minimum \( r_{c,\min}^{i} \) and maximum \( r_{c,\max}^{i} \) levels of curiosity:
To sum up, if the prediction error and the corresponding curiosity are high, the normalized value will be 0, otherwise close to -1. The total reward \( r_{t}^{i} \) at a time step t that is received by layer i consists of extrinsic \( r_{e,t}^{i} \) and curiosity \( r_{c,t}^{i} \) rewards. It is controlled by the hyperparameter \(\eta\).
Figure 3: The CHAC Architecture with two layers of hierarchy Röder et al. (2020), with a forward model in each layer to compute the prediction error and use it as curiosity-based reward \( r_{c,t}^{i} \) for layer i. This reward is called the intrinsic reward and it is added to the extrinsic reward \( r^{i,e} \), which is given from the environment.
4.6 The Regularization of the Subgoal Representation
In deep learning, as in most numeric algorithms, there is a trade-off between learning stably and learning fast. For instance, training a neural network with small learning rates provides better stability but leads to lower learning (Goodfellow et al., 2016). This is also crucial for HAC: learning the sub-goal representation \(\phi(s)\) could improve exploration efficiency, but stable learning contradicts fast learning (Li et al., 2022). Thus, to solve this dilemma, the authors in Li et al., 2022 proposed a novel state-regularization \( L_{s} \) of the sub-goal representation to limit the representation changes during each update:
\( L_{s} = E_{s \sim B} [ \lambda(s) \| \phi(s) - \phi_{old}(s) \|_{2} ] \),
where B is a replay buffer, and \(\lambda(s)\) is a function that controls the states' weights of regularization, which should be high for states with small representation losses, as these fit the learning objective well. In practice, the authors rank the states and set \(\lambda(s)\) to zero for all states except those \(k\)% with the minimum representation losses; Li et al., 2022 set \(k = 30\).
For improving the representation learning efficiency without disabling its stability, the authors used prioritized sampling (Hinton, 2007), which is an adaptation of importance sampling. In prioritized sampling, the probability of the positive samples, i.e., actions or sub-goals leading to a reward with a large value, is 0.1 instead of 0. In case a positive sample is chosen, then the computed gradients are multiplied by a small value. In Hinton, 2007 a coefficient of value 10 is used, while in Li et al., 2022 a value of 1e-3 is used.
5 Implementation
For implementing CHAC, we used the author's implementation Röder et al. (2020) to get a fair comparison between CHAC with the regularization of the sub-goal representation added and vanilla CHAC. We implemented the regularization technique proposed by Li et al. (2022) to stabilize the learning of the subgoal representation. Additionally, we added the regularization technique to CHAC. Lastly, we refactored the author's code of CHAC, restructured it and added more documentation to the code to make it easier to follow.
5.1 Curiosity Hierarchical Actor-Critic
The authors (Röder et al. 2020) implemented the curiosity using a forward model that concatenates current state \(s_{t}\) and action \(a_{t}\) and generates the predicted subsequent state \( \hat{s}_{t+1} \).
The forward model is implemented as a Multi-Layer Perceptron (MLP) of 3 hidden layers of size 256. According to (Röder et al. 2020), this setting provides the best performance. The actor and critic networks are MLPs of 3 hidden layers of size 64 (Levy, Konidaris, et al., 2017). All networks are trained with a learning rate of 1e-3 using the ADAM optimizer (Kingma & Ba, 2014). After each episode, the networks are trained by randomly taking 1024 samples from the replay buffer. All of the used parameters are adapted either from HAC (Levy, Konidaris, et al., 2017) or fine-tuned with preliminary experiments (Röder et al. 2020). We used two levels of hierarchy, as the authors mentioned in their implementation 2.
Each actor network learns a limited length policy, i.e., the actor-network executes a certain number of actions to achieve the sub-goal assigned to it by a higher level actor-network (Levy, Platt, & Saenko, 2017). The authors in (Röder et al. 2020) used different time limits for the different hierarchical levels, namely, for the first and highest level of hierarchy 25 and the lowest level 10 3. We used 27 as a time limit for both levels because it provides better performance. For balancing the extrinsic rewards and the curiosity, the authors used a default value of \(\eta = 0.5\)4, but it is mentioned that different values of \(\eta\) in different environments yield different performances (Röder et al. 2020). The authors of CHAC added different noises to the sub-goals and actions to ensure sufficient exploration. 5
5.2 The Regularization of the Sub-goal Representation Learning
Li et al. (2022) used two measures, namely a novelty measure and a potential measure, to incentivize the agent to explore novel and effective sub-goals. They did not use any intrinsic rewards in their proposed algorithm. Thus, we kept the curiosity-based intrinsic rewards suggested in Röder et al. (2020), but we added their regularization of the sub-goals learning. We implemented the representation network 6 as Li et al., 2022 in their implementation suggested, as an MLP with one hidden layer of size 100 and an encoder to represent the sub-goals. We updated the sub-goal representation every 100 episodes, which Li et al., 2022 referred to as the Representation Update IntervalI and they proposed using a value of I in range of \(50 \leq I \leq 150\). If the update happens frequently, for instance, \(I = 50\), then the learning of sub-goal representation becomes less stable. If the update happens every 500 episodes, the learning becomes very slow and difficult (Li et al., 2022).
Prioritized sampling helps improve learning efficiency. Thus, Li et al., 2022 ranked the data in the replay buffer and chose the top \( 30% \) of the data with the minimum representation losses. Their implementation differs from the paper, where they used a stable coefficient of size 1e-3 for all the states instead of \( \lambda \), which should be greater than 0 for the states with small representation losses and equal to 0 for the states with larger representation losses 7. Additionally, in the implementation of Li et al., 2022, the authors considered the bottom \(50%\) of the data with the minimum representation losses to compare them with the top \(30%\) to give the states with fewer representation losses a higher probability of being sampled for training. We ranked the data in the replay buffer according to the critic's evaluation to encourage the representer network to produce sub-goals that improve the performance.
6 Experimental Setup
Röder et al. (2020) used six multi-goal-based environments with continuous state and action spaces. These environments give very sparse extrinsic rewards, namely once a complicated goal is achieved. Röder et al. (2020) measured their algorithm's performance using success rate, which is the average number of successful testing rollouts within a test batch.
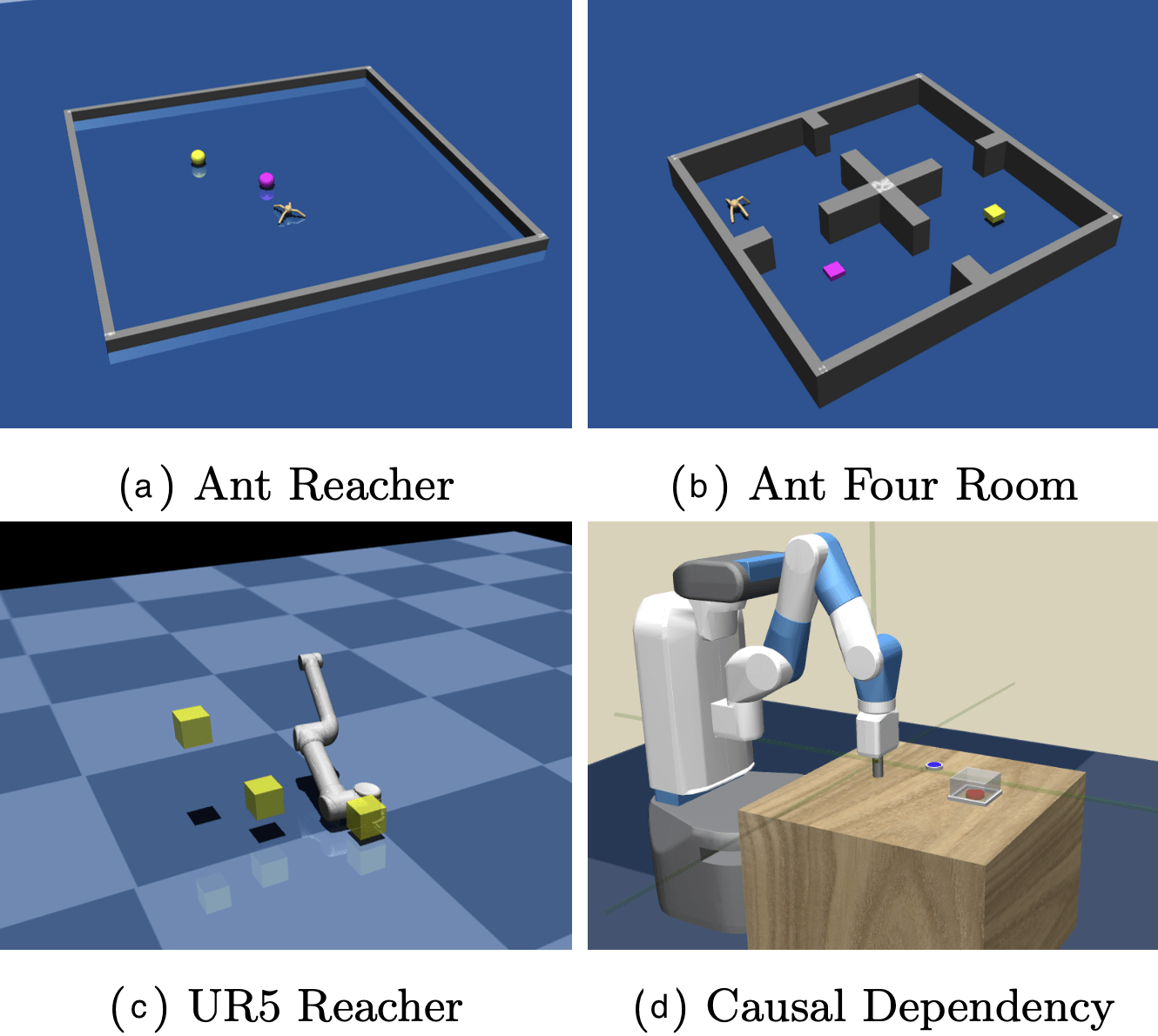
Figure 4: The simulated environments for experiments taken from Röder et al. (2020)
6.1 Environments
We evaluated our algorithm by using the following four MuJoCo 8 environments (Figure 4):
Ant Reacher: A four-legged robot has to move to a specific position. If its torso reaches the position, a reward is given. The actions are based on the single joints of the robot (Röder et al. 2020).
Ant Four Rooms: The only difference between this and Ant Reacher is that there are walls dividing the environment into four rooms, so the agent has to navigate through the holes in the walls, making it more difficult (Röder et al. 2020).
UR5 Reacher: The environment contains a robotic arm with three moving joints that have to be in a specific configuration to get a reward (Röder et al. 2020).
Causal Dependency: A robotic arm must press a blue button which removes a barrier to the target location, making the latter accessible. It then has to move to the target location (Röder et al. 2020).
7 Results
The hierarchical learned policies are evaluated by taking the average of the last four episodes. Due to the limited resources and time pressure, we ran the experiments only for 100 epochs, which is usually not sufficient to judge the failure or success of an algorithm. Multiprocessing is used in the code, where hyperparameters need to be passed to the training 9. We also applied a bit of smoothing to the results. For each run, we created an experiment script 10 with the values of hyperparameters to reproduce the results. For the Ant Reacher environment with \( \eta = 0.75\), the performance of both algorithms is poor due to underfitting, as shown in (Figure 6). The regularized CHAC performance is slightly better thanks to the sub-goal representation learning (Figure 5), which seems to allow more exploration than CHAC. We also updated the representer according to both the representation loss and the critic loss. Thus, the critic's performance affects the overall performance.
Figure 5: Success rates of regularized CHAC vs. CHAC in AntReacherEnv-v0, the x-axis is the training epochs.
Figure 6: Success rates of regularized CHAC vs. CHAC in AntReacherEnv-v0 during training.
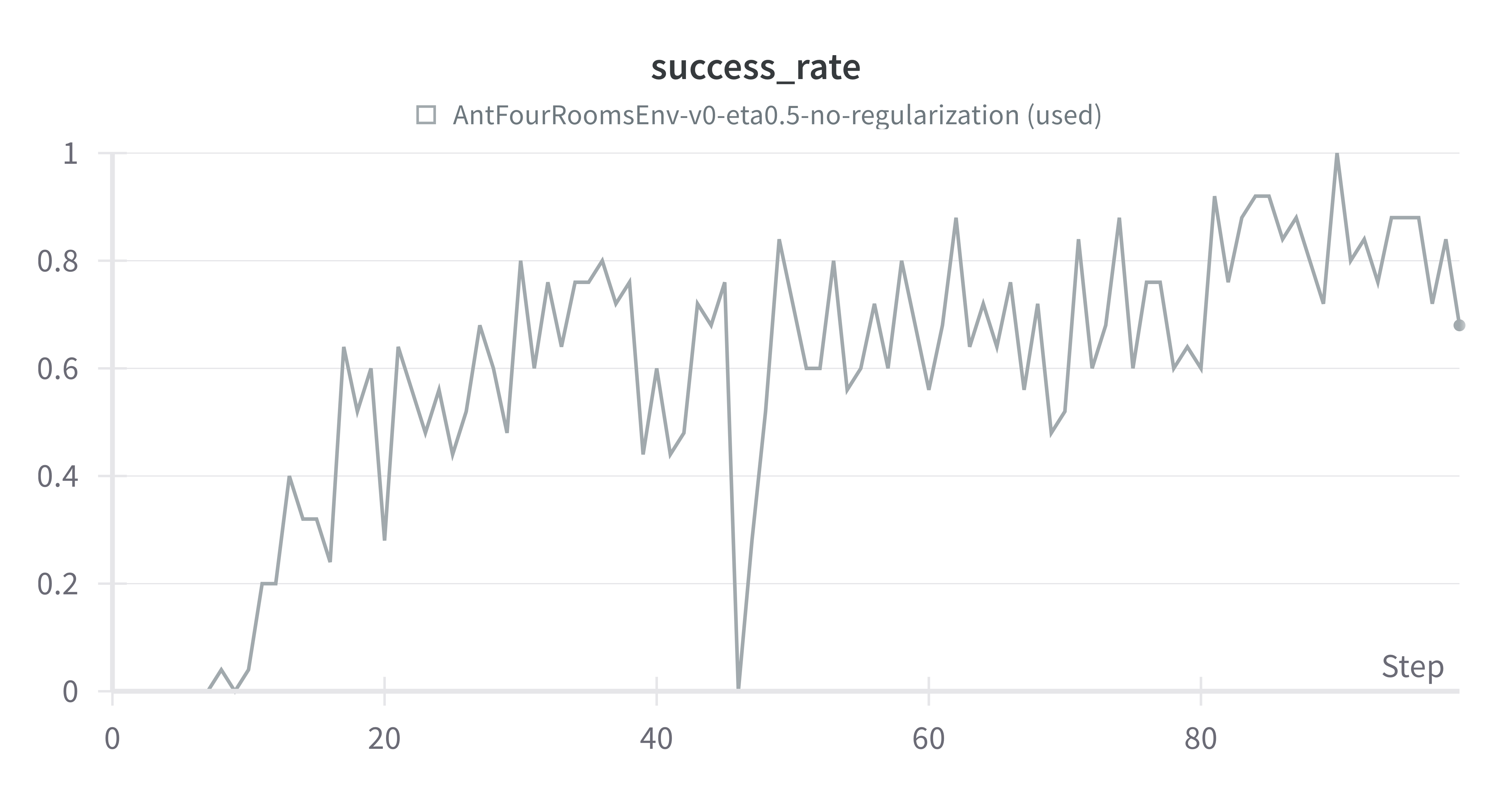
As we see in the Ant Four Room environment with \( \eta = 0.5\), the regularization, in this case, affects the learning negatively, where the learning is slow. But in the non-regularized case, the learning might improve faster, as shown in (Figure 7).
Figure 7: Regularized CHAC vs. CHAC in AntFourRoomsEnv-v0.
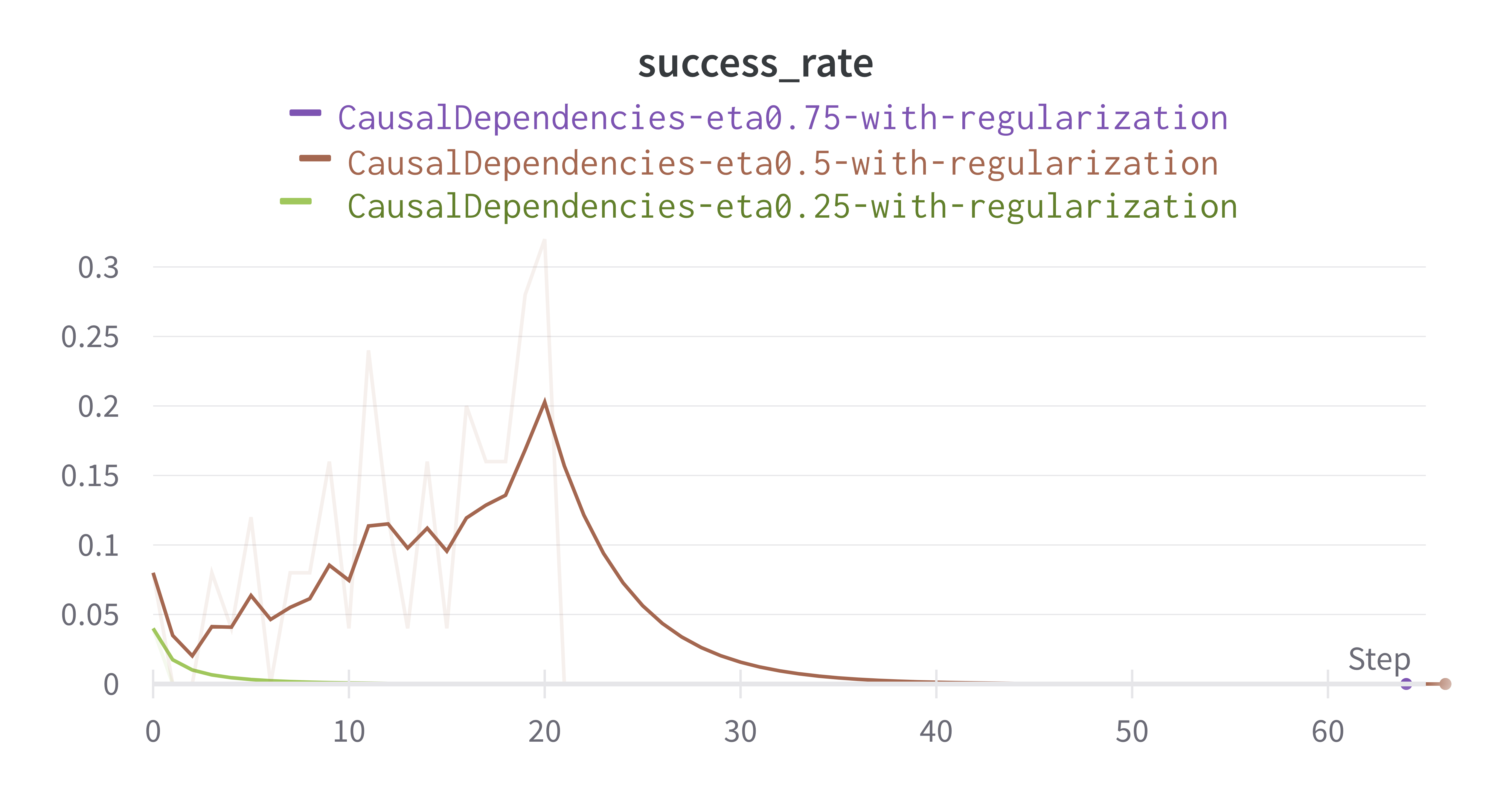
While in the causal dependencies environment with \( \eta = 0.5\), the regularization, in this case, affects the learning positively, where the learning is faster, and the agent can explore effectively. In the vanilla CHAC, the performance during the first 90 episodes is considerably worse than in RCHAC, as shown in (Figure 8).
Figure 8: Regularized CHAC vs. CHAC in CausalDependencies.
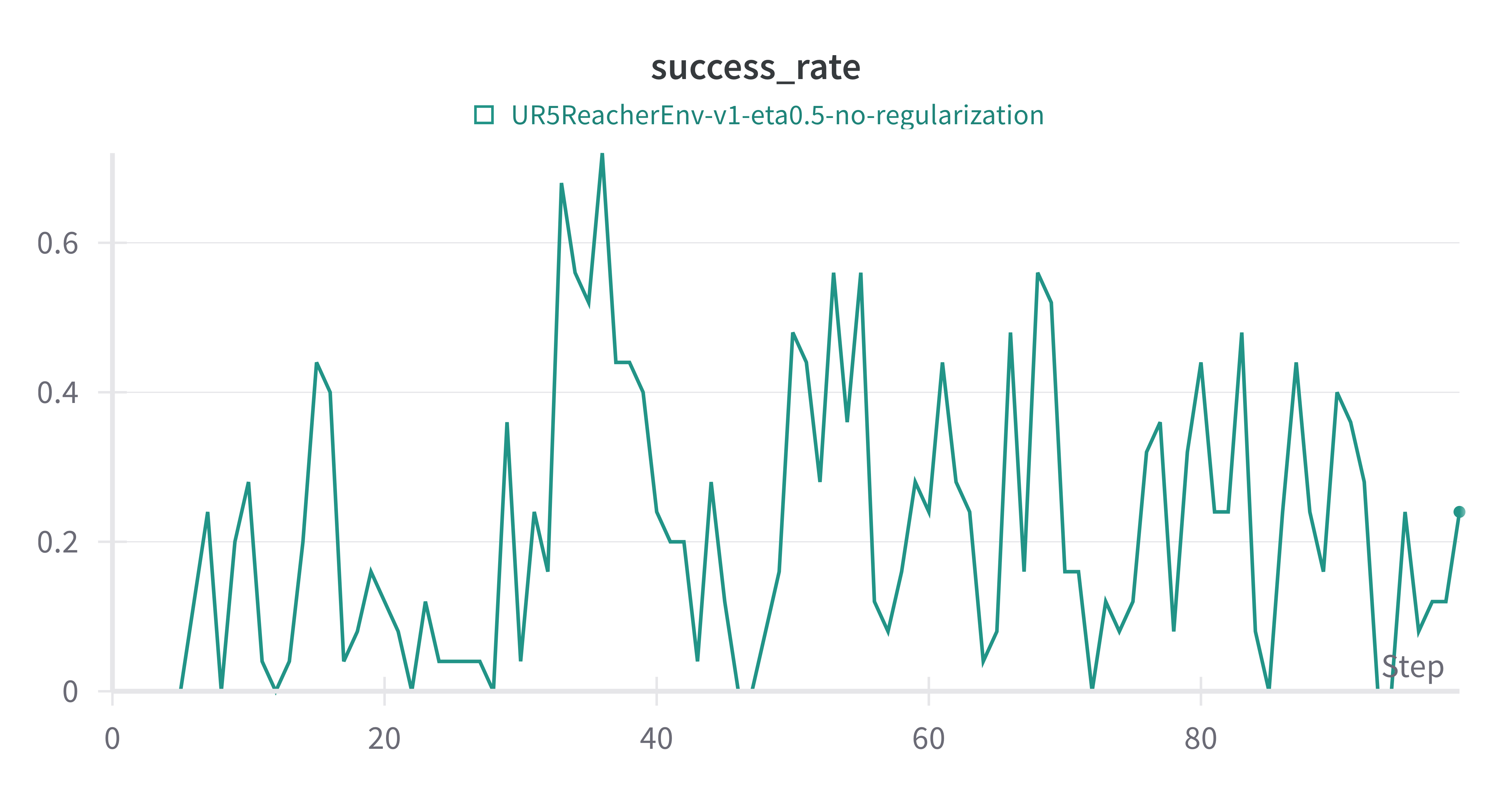
In UR5 Reacher, RCHAC does not perform better than CHAC. The regularization, in this case, made the learning slower. CHAC, in (Figure 9), learns but in an unstable manner.
As mentioned previously, both algorithms should run for thousands of steps and many runs to judge adequately on the performance. We also noticed that \( \eta \) and the time resolutions are major and task-dependent hyperparameters, as mentioned by Röder et al. (2020). Thus, we did ablation studies on these two hyperparameters to see their effects on the proposed algorithm RCHAC.
Figure 9: Regularized CHAC vs. CHAC in UR5 Reacher.
7.1 Ablation Studies
For each actor network, it is crucial to specify the time limits in a different temporal resolution as they help divide a sequence of actions to achieve a goal into multiple sequences of different time resolutions, where each sub-sequence reaches a sub-goal. (Levy, Platt, & Saenko, 2017). The limited policies allow easier learning of shorter policies in parallel rather than learning a long policy. However, this creates a new dilemma---the sub-goal actor networks have conflicting objectives (Levy, Platt, & Saenko, 2017). Each sub-goal actor network learns a policy that should simultaneously achieve the goal of the higher level in as few sub-goals as possible and produce a sub-goal that the lower-level actor network can achieve in a few steps. Levy, Platt, & Saenko, 2017 suggested 10 timesteps for two levels of hierarchy. While Li et al., 2022 used for 25 and 10 timesteps for two hierarchical levels, respectively 11. We also used 27 timesteps for both levels.
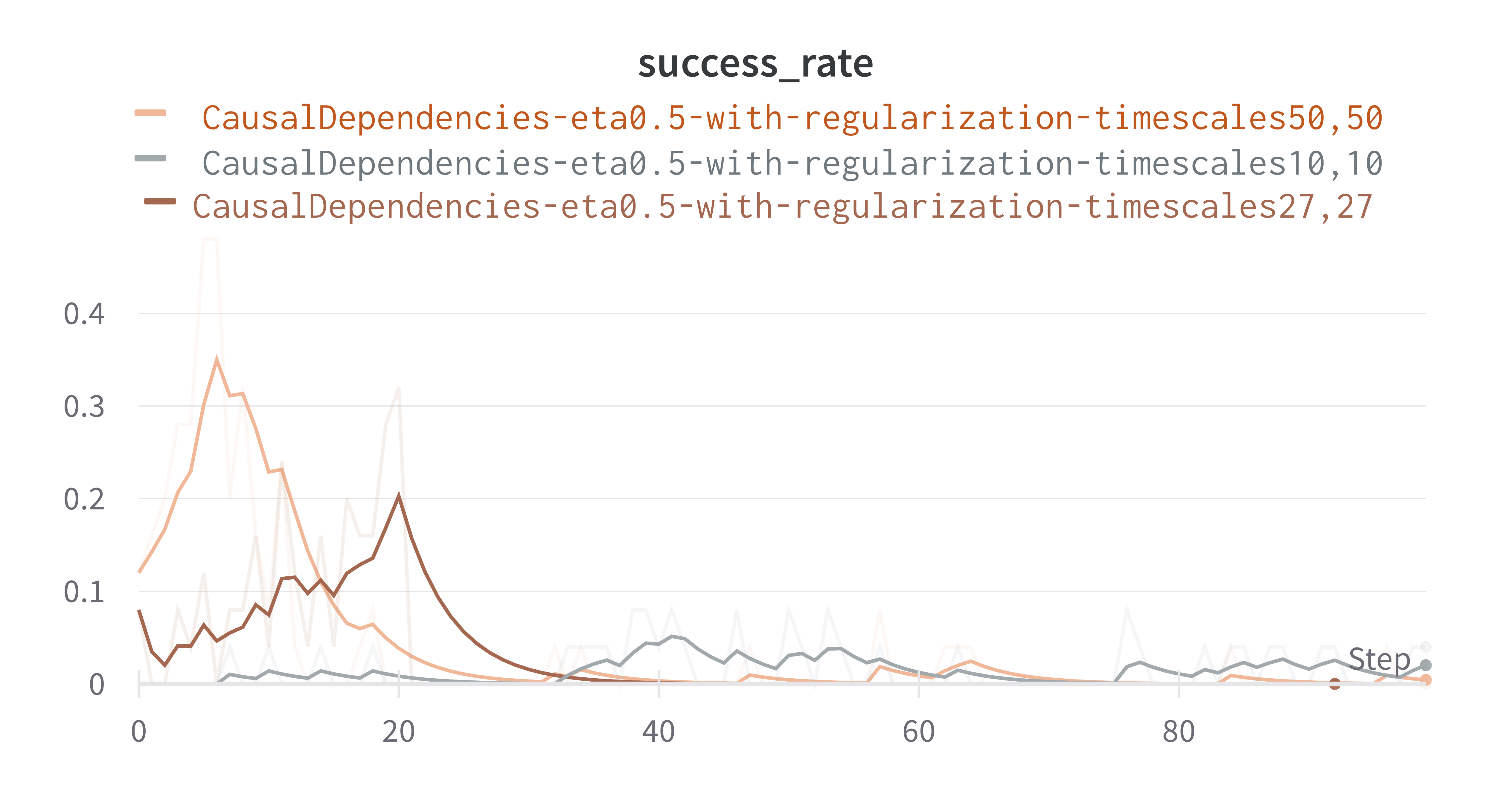
As we see in Figure 11, running our regularized version of CHAC in the Causal Dependency environment with time scales of 50 for the two hierarchical layers provides better performance when the time scales of 10 for the two layers are used. This performance improvement is due to the agent performing longer sequences of actions, which allows the agent to explore more. A long trajectory helps the agent gather a higher sum of rewards, especially in an environment with sparse rewards, but this will also create a larger number of sub-goals in the first hierarchical layer. This hyperparameter for both layers should be carefully selected due to its impact on the performance.
For balancing the extrinsic and intrinsic rewards, Röder et al. (2020) used η of size 0.5 as a default value (Figure 11). The authors already experimented with different values for η, and they found that the benefits of curiosity depend on the task. Curiosity-based exploration helps better when the environment is difficult to solve. Otherwise, HAC suffices for easier environments. We also witness the major role of η as we can see in (Figure 10), where CHAC with different values of η acts differently. It might be due to whether the agent is awarded more by curiosity, by the environment, or equally by both. In (Figure 10)η of value 0.
helped improve the performance. This hyperparameter can be fine-tuned carefully depending on the task because of its important effect on performance.
Figure 10: The role of \( \eta \) in RCHAC when used in the causal dependencies environment.
Figure 11: The role of the different values of time scales in RCHAC when used in the causal dependencies environment.
8 Conclusion and Future Work
8.1 Future Work
Extensive experimentation regarding the effect of time scales should be conducted as it is a crucial hyperparameter that affects the exploration negatively if it becomes a smaller or larger value, as we saw in the experimentation. \( \eta \) should be chosen carefully, as we saw in the ablation studies 7.1 and as mentioned by Röder et al. (2020). For fine-tuning the parameters, we would use the experiment tracking using Weights & Biases 12. Running many experiments for a large number of episodes would allow us to judge the two algorithms better and select optimal values for the used hyperparameters. We might be able to understand in what kind of environment the curiosity would help or even harm. The same applies to the proposed regularization technique. We think that trying other regularization techniques would help determine the optimal one to use in the implementation of CHAC.
8.2 Conclusion
The proposed method, in some configurations, does slightly improve the performance. HAC performs well in uncomplicated environments but poorly in challenging ones. CHAC improves HAC using curiosity-based rewards only to a certain extent. CHAC also requires prior knowledge of the sub-goal representation space to produce proper curiosity-based rewards, while the regularized learning of the sub-goal representation does not require that kind of knowledge to produce proper intrinsic, i.e., curiosity-based, rewards. The regularization might harm the learning if the used models are underfitting. However, in some environments, we have seen improvement in the performance of CHAC when used with regularization. This means that the CHAC can be improved using regularization techniques.
References
Anca, M., & Studley, M. (2021). Twin delayed hierarchical actor-critic. 2021 7th International Conference on Automation, Robotics and Applications (ICARA), 221–225.
Bacon, P.-L., Harb, J., & Precup, D. (2017). The option-critic architecture. Proceedings of the AAAI Conference on Artificial Intelligence, 31 (1).
Ciaburro, G. (2018). Keras reinforcement learning projects. Packt Publishing.
Dayan, P., & Hinton, G. E. (1992). Feudal reinforcement learning. Advances in neural information processing systems, 5.
Fedus, W., Ramachandran, P., Agarwal, R., Bengio, Y., Larochelle, H., Rowland, M., & Dabney, W. (2020). Revisiting fundamentals of experience replay. International Conference on Machine Learning, 3061–3071.
Pathak, D., Agrawal, P., Efros, A. A., & Darrell, T. (2017). Curiosity-driven exploration by self-supervised prediction. ICML.
Röder, F., Eppe, M., Nguyen, P. D., & Wermter, S. (2020). Curious hierarchical actor-critic reinforcement learning. International Conference on Artificial Neural Networks, 408–419.
Russell, S., & Norvig, P. (2020, May). Artificial intelligence: A modern approach, global edition (4th ed.). Pearson Education.
Schaul, T., Horgan, D., Gregor, K., & Silver, D. (2015, July). Universal value function approximators. In F. Bach & D. Blei (Eds.), Proceedings of the 32nd international conference on machine learning (pp. 1312–1320, Vol. 37). PMLR. https://proceedings.mlr.press/v37/schaul15.html.
Does adding the regularization of the subgoal representation learning improve the Curiosity Hierarchical Actor-Critic framework without prior knowledge about designing the sub-goal spaces.